



Back in 2018 and 2021, DeeperThanBlue challenged analytics platforms to predict the outcomes of football matches played at the FIFA World Cup and the UEFA European Championship.
With an office full of football fans (and some people who watch Sheffield Wednesday) it’s a great way to demonstrate our analytics skills while having some fun.
For Euro 2024, tech has moved on, so we’ve brought AI into the squad. With predictions also coming from humans (novices and experts alike) and even cats, it’s game on!
Back in 2018, we applied some simple predictive techniques to predict the outcome of each of the 64 world cup football matches, leveraging IBM Watson Analytics, and demonstrated how the modelling uses the results to effectively ‘learn’.
In 2021, we extended the complexity of the predictor and utilised IBM Planning Analytics and Microsoft PowerBI for data visualisation.
This time around we are flexing our AI muscles to see how Traditional and Generative AI can be applied to the process. We made it tough for ourselves, giving ourselves just one week to develop a process which could deliver the predictor show above in time for the opening game.
Squad Selection
We wanted to build an AI model which would help us to gain insights into the possible outcomes of the matches taking place during EURO 2024.
We want to use AI wherever possible, but to play to its strengths, and highlight its limitations as part of the process. For the group stages, we developed a machine learning model, using the results of international games stretching back to 2018, some 5,500 matches to predict the outcome of each game. This traditional AI model pushes results predictions into BigQuery hosted on the Google Cloud Platform (GCP), with data visualisation handled by Google Looker Studio.
Generative AI models are based on Large Language Models which are trained on base data from a fixed point in time. When you interact with a model, it’s responses are based on that base of information. You can fine tune an LLM with new data, but it’s expensive. Alternatively you can use prompt engineering, and RAG to direct the model to any real-time data that it should use as part of the response it provides.
We chose this approach, pointing our WatsonX Virtual Assistant to point to the prediction data in BigQuery to provide predictions based on questions we ask. We plan to gradually improve the scope of this Virtual Assistant to become a full blown AI Pundit, we called it “Harry”.
A Blend of Youth and Experience

Christiano Ronaldo through the ages!
We also wanted to compare how this prediction fared against that of humans with different levels of knowledge of football to see if the AI modelling based on large data sets could compete with the nuanced understanding that humans possess. This human understanding was taken from DeeperThanBlue’s staff and partners, as well as sporting pundits who make money from their expert knowledge.
Feline Punditry

Phil Foden and Felix Foden (not Chester or Jinx)
Then, because everyone loves a novelty prediction, we encouraged Chester and Jinx (my cats) to pick the outcome for each game by indicating on the teams’ flags. There’s nothing scientific about this, but you could say that it considers how chance and random selection might also compare to more insight-based predictions!
Training Camp
The time allowed to prepare the team for the tournament was tight, and we took the approach to field Team-AI with a skeleton squad (or minimal viable product) knowing that we could revisit the strength and depth of the squad throughout the competition.
Our initial model takes the base data and applies a gradient boosting classifier and gradient boosting regression algorithms. The data is updated following each game and the results prediction data is refreshed. The model does apply additional weight to the most recent 5 games as a form indicator.
Pundit information is scraped automatically from a number of trusted third party sites. Odds from leading UK bookmakers are gathered using Mantronics (OK we type it in as the bookmakers’ sites tend to block screen scrapes!)
We then use WatsonX Assistant as our interaction client, pointing to the WatsonX.ai platform using the open source Llama 3 LLM. (More details to follow in technical deep dive article.)
We then ask “Harry” “what do you predict for todays game” and receive the predictions.
A game of two halves
We’re currently at the end of the group stages and our league table looks like this:
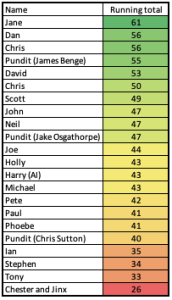
Points are awarded as follows:
- Predicting the correct outcome (winner or draw) = 2 points
- Predicting the correct outcome and the correct score = 5 points
- Any other prediction = 0 points
What does this say about the AI model?
To date, the AI predictor has shown a reasonable ability to predict match outcomes (17 correct outcomes and 3 correct score lines out of 36 matches), Not world-beating, but not a complete failure either.
We have updated the base data and predictions after each round of matches to help tune the predictions based on recent results. But it occurred to us that tournament momentum, either positive or negative, is not factored in. Neither is the loss of a key player through injury or suspension, so we have adapted the ML model to factor this in for the knockout rounds. Knockout-rounds “Harry” is also getting an upgrade, and we look forward to sharing his insights!
What does this say about the human predictions?
We have had some stellar performances from our staff and partners, notably Jane who has been particularly good at predicting score lines (17 correct outcomes with 9 correct score lines), and Joe, Chris, Chris and David all predicting 19 correct outcomes.
There are others (ahem) who should have been left in the dressing room, or perhaps should have known better than to take part in the first place!
It should be noted that we asked for all match predictions before the tournament started, so we’ve not been able to reflect player changes and teams performing above or below par. As we move into the knockout phase of the tournament, there may be some changes of opinion.
And what about the cats?
The cats’ performances shouldn’t be underestimated. OK, they have sometimes needed incentivising to participate, but on the whole they’ve been compliant. Their position in the table disguises a significant handicap that they have. The humans and AI predictor have all been able to predict the outcome and the scoreline, whereas the cats can only pick the outcome. So, for each result they get right they only collect 2 points, while the other predictors could get 5 points for correct outcome and score.
If we generously assume that they would have got the score correct for a third of their correct predictions, after the group stages they would have earned 46 points and comfortably sat in mid-table.
Half-time press conference
We moved fast, kept possession and have delivered a strong first half performance.
We have shown that it is possible to create a functional AI driven capability in a very short timeframe.
As we move into the knockout phase, we’re preparing to field a stronger team. We’ll bring in the might of WatsonX to power as AI assistant which will power an interactive source of knowledge able to answer questions about the games.
We’ll also do further fine-tuning to the prediction model using additional, more nuanced data, such as in-tournament performance (are they playing above or below par) and the impact of player changes through injury or suspension).
We’ve also got to find a way to keep the cats engaged for another couple of weeks. This might end up costing me a fortune in Cat Treats!

Chester and Jinx at their training camp.